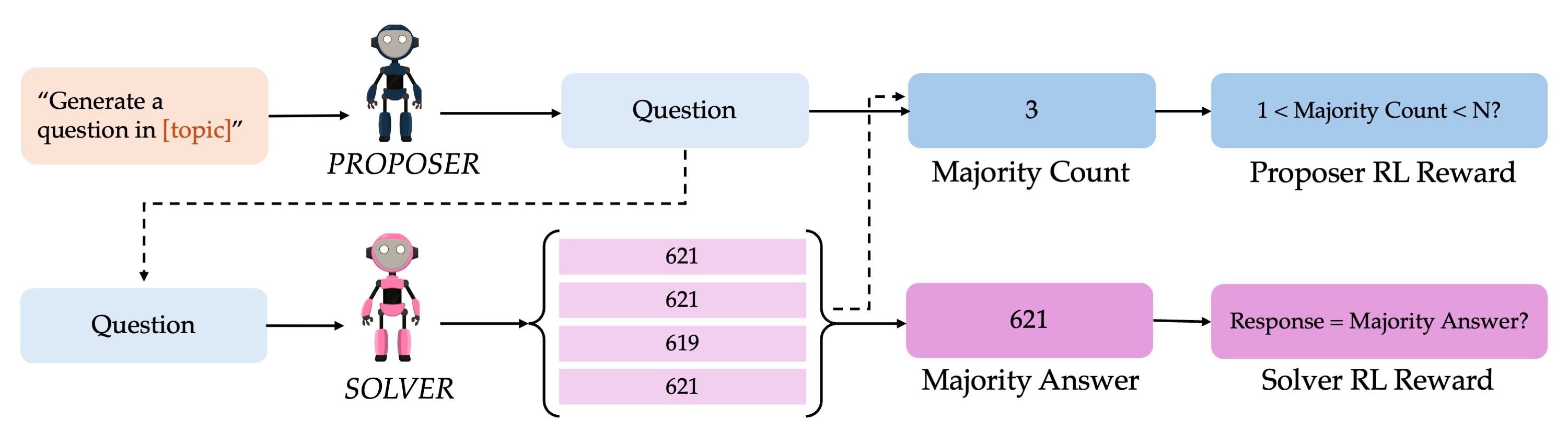
We train two policies in a self-play setup: a proposer policy
\(\pi_{P_t}(x)\) that generates problems and a solver policy
\(\pi_S(y_{\text{pred}} \mid x)\) that attempts to solve them. Both are optimized
via reinforcement learning to maximize their expected rewards:
\[
\text{Solver: } \mathbb{E}_{x \sim \pi_{P_t},\, y_{\text{pred}} \sim \pi_S}[ \mathcal{R}_S(x, y_{\text{pred}}) ],
\quad
\text{Proposer: } \mathbb{E}_{x \sim \pi_{P_t},\, y_{\text{pred}} \sim \pi_S}[ \mathcal{R}_P(x, y_{\text{pred}}) ]
\]
The proposer's problems condition the solver, and the solver's performance provides rewards
that in turn refine the proposer. Since there are no ground-truth answers, we design
self-supervised reward functions based on the generator-verifier gap.
Small generator-verifier gap (e.g. arithmetic): verification is as
difficult as generation. We use majority voting as a proxy reward:
\[
\mathcal{R}_S(x, y_i) =
\begin{cases}
1 & \text{if } y_i = y_{\text{maj}}, \\
0 & \text{otherwise}
\end{cases},
\quad
\mathcal{R}_P(x) =
\begin{cases}
1 & \text{if } 0 < |\{y_i = y_{\text{maj}}\}| < N, \\
0 & \text{otherwise}
\end{cases}
\]
Large generator-verifier gap (e.g. coding): verification is easier than
generation. The proposer generates test cases, and rewards are based on the fraction of
tests passed:
\[
\mathcal{R}_S(x, y_{\text{pred}}) = \text{Pass}(y_{\text{pred}}, \text{Tests}(x)),
\quad
\mathcal{R}_P(x, y_{\text{pred}}) =
\begin{cases}
1 & \text{if } 0 < \text{Pass}(y_{\text{pred}}, \text{Tests}(x)) < 1, \\
0 & \text{otherwise}
\end{cases}
\]
This minimax formulation enables stable training through self-play while adapting
reward design to the problem domain.